Structure in Unstructured data: Using AI for Data Security

Chaos is defined as the characteristic of a system (generally, anything) which makes it harder to understand, and subsequently complex to predict. It’s been decades since Lorenz performed his little simulation (famously known as the Butterfly Effect) proving patterns underlie chaotic phenomena like weather conditions and galaxies.
Today, organizations face a problem very similar to understanding such complex phenomena. For each organization it is ubiquitous but unique, known but unmanageable, and it is as big as it is costly. The idea of analyzing information stored in data lakes with pettabytes of unstructured data ranging from video files, audio files, textual files, annotated logs, images, etc. being generated at an ever increasing rate every year over the last few decades is nothing less than an engineering nightmare.
These data lakes store much valuable information that similar to weather patterns seem impenetrable at first, but if looked at closely, project hints and conspicuous patterns. If used prudently, these patterns can lead to extremely valuable insights and not only help smart people develop amazing use cases, but also provide unparalleled business value.
Structured and Unstructured Data
Structured data is any data that can be passed and returned using queries. Effectively, structured data can be stored in relational databases, can have through connections, and can be easily visualised into tables and columns. Given a query, the underlying structure, that is schema, defines rules on how the data will be returned.
Unstructured data on the other hand is any data that is not explicitly structured. This can include video files, audio files, images, text containing documents like PDFs etc. Effectively, unstructured data is found everywhere and is generated at the rate four times more than that of structured data. Unlike structured data, unstructured data cannot be queried using traditional querying languages. It requires a lot of analysis to be able to effectively parse and make it useful for end-users and analysts alike.
The Age of Unstructured Data
In November 2022, OpenAI publicly released their most user friendly transformer based model ChatGPT, trained over 570GBs of unstructured data. Within 6 months they projected $1 billion in revenue by end of year 2024. While this is an extreme example of the value of unstructured data, it vividly illustrates its importance and ability to lead the future technological advancements.
Grounded examples might include, companies modelling CCTV footages to monitor workplace accidents to capture and effectively generate evidence for insurance claims, companies annotating publicly shared visual information like photos and videos to censor inappropriate posts, and organizations discovering and labelling sensitive information for better data security and compliance needs.
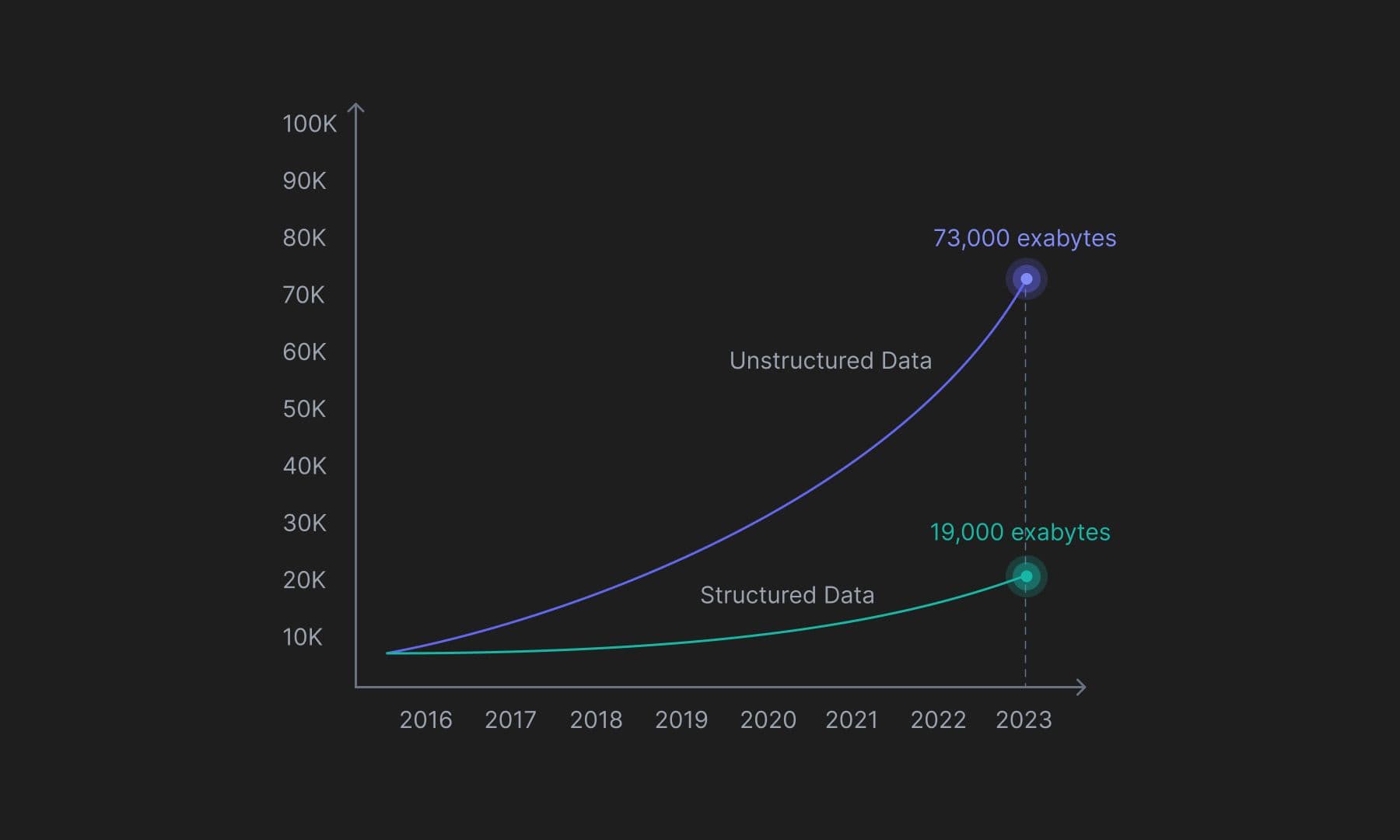
In 2023 alone, organizations globally are expected to generate over 73,000 exabytes of unstructured data, which is approximately 4 times the amount of structured data expected to be generated. With so much data flowing every second, and despite having solid models to make sense of it, not knowing it exists can limit an organization’s capabilities. Effective capture of recognizable patterns needs to be in place more than the individual bits of contained information itself.
How AI finds Structure in Chaos

Machine Learning models essentially burn down to software architectures designed to efficiently go through large amounts of information and identifying underlying patterns.
Historically, they have been trained on structured data (supervised learning), to make predictions and classify data. But, since the introduction of the transformer architecture (2017) which enabled researchers and engineers to train models that are really efficient (compared to old, slower models) in understanding relationships (patterns) in unstructured data, the world of AI has exploded.
Artificially Intelligent models, in this sense, are able to understand data and how each piece of contained information relates to other pieces of contained information. These connections or patterns can then be used to further identify relevant information, based on a input-out inference structure. Such high performance models make good foundation, but are rarely applied directly in the real world.
An industrial strength architecture needs sophistication to work reliably and also to handle edge cases or faults. Directly applying a model trained on unstructured data seems to provide false positives more than the tolerance allows. Engineers have developed and designed many architectures to effectively ensure the capture of patterns, not easily comprehendible by humans.
For example, a simple architecture designed to extract relevant information from PDFs might involve multiple moving parts as detailed below—
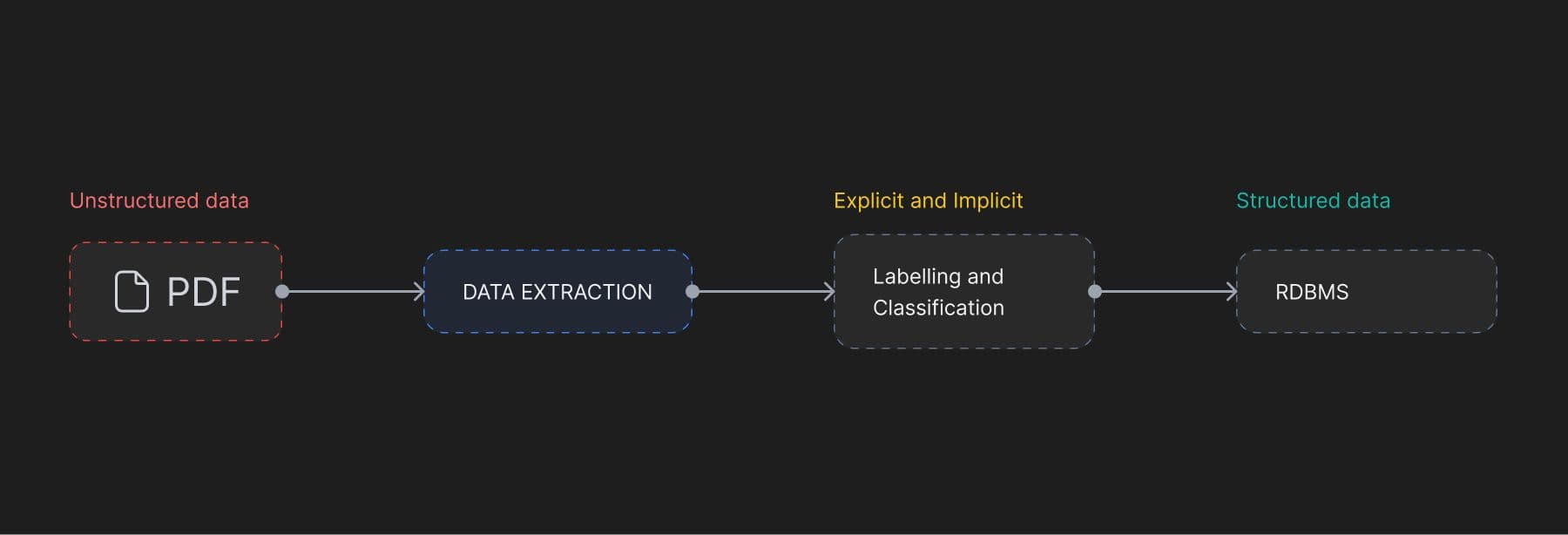
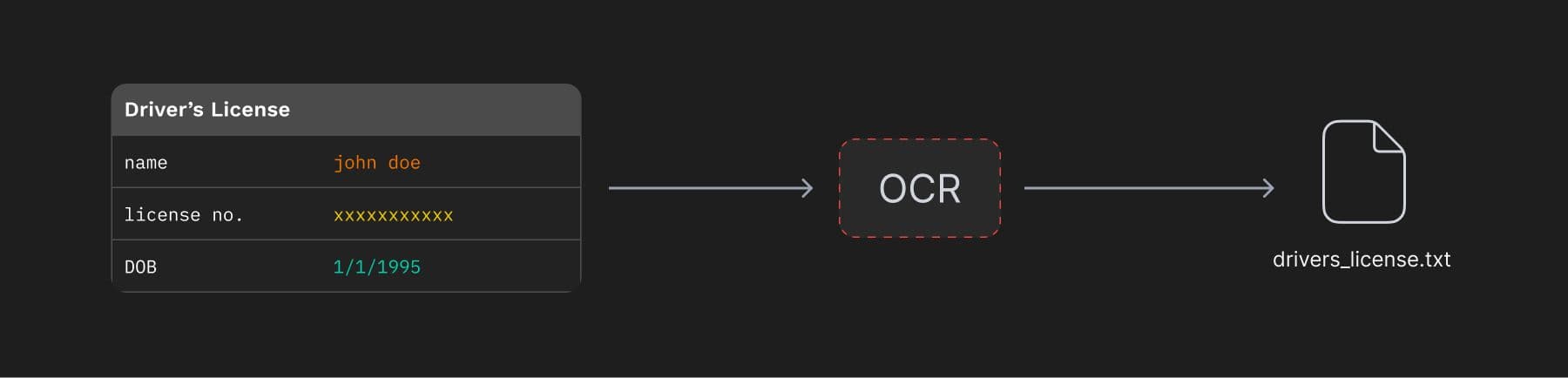
- Text is extracted using extraction libraries or OCR applications, e.g. PDFs containing scanned images of many driver’s licences
- Text can then be passed through an AI Model which then extracts relevant bits of information and stores it in memory, e.g.
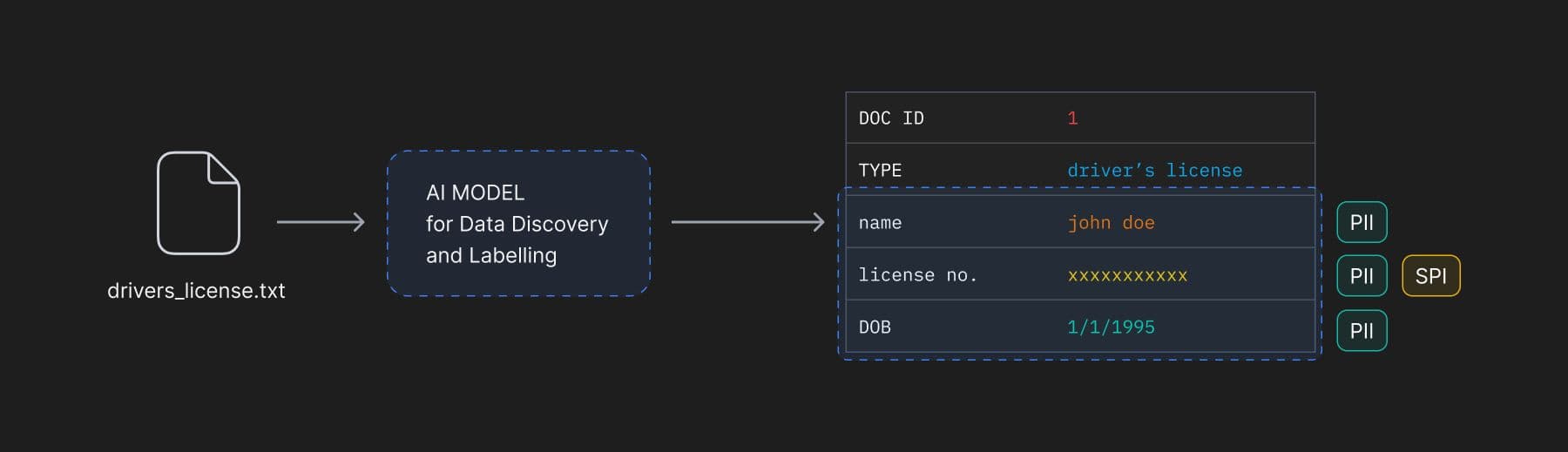
- For each bit of information in the memory, a data store is updated creating a link between the information and it’s type.
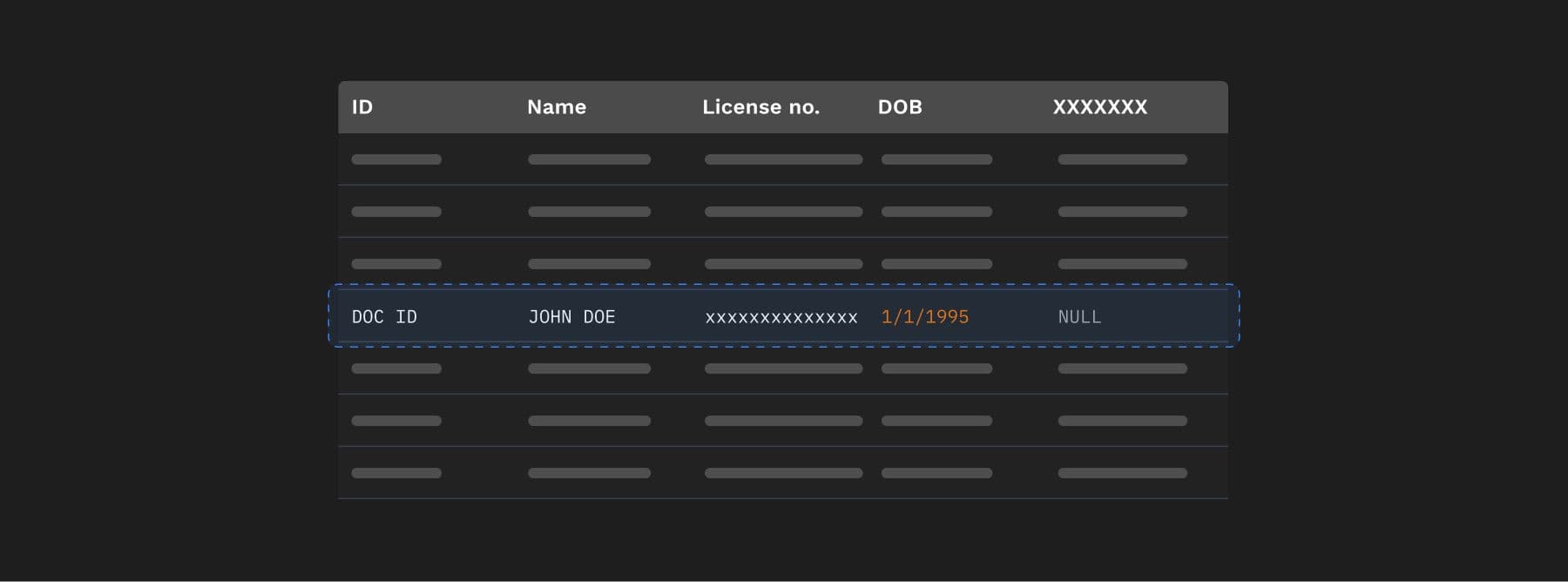
- If a new type is discovered, say ‘son of’, it needs to be duly updated in data store before adding the information to it.
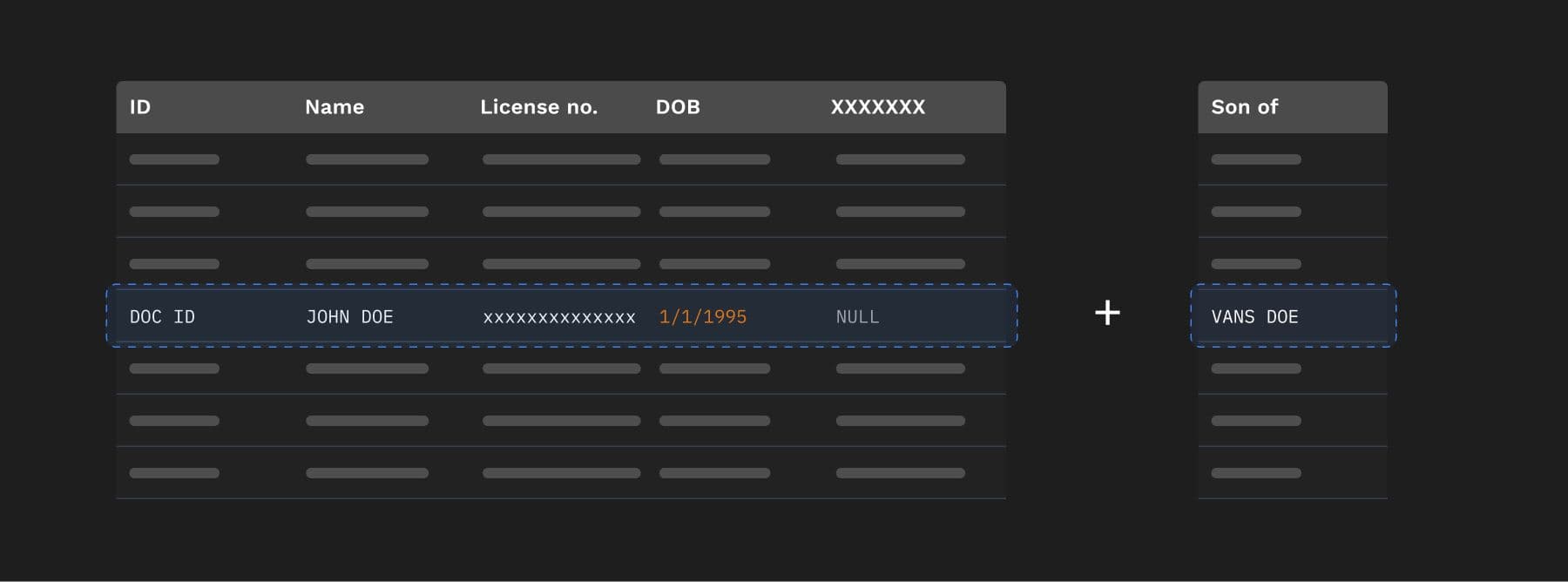
- Knowledge of these relations can then bring business value for organizations
Understanding the Real World Applications
The biggest challenge that data teams face isn’t the collection, but creation of value out of seemingly un-quantifiable and limitless information reserves. Every organization of today’s age is collecting data on a regular basis, but few have effectively captured patterns and consequently delivered great business value. Some use cases of finding patterns from unstructured data are discussed here.
Checking Inappropriate Content - Once the architecture flags some content as inappropriate, alerts can be made for content control teams to review, or for apps requiring strict adherence to regulations, flagged content can be hidden without any human intervention.
Designing Better User Experiences - For user facing organizations generating content for consumers, flagging types of content and even going the extra step to analyze videos and creating annotated timestamps can help create user value by saving time and curating more personalized content.
Discovering and Labelling Sensitive Data - More often than not, sensitive information in unstructured data can’t be recognised by heuristics alone and therefore probabilistic models can be employed to flag information that is similar to some type of sensitive information and later labelled and classified to incorporate a stronger data security posture for the organization.
Improving Security Posture by Using Unstructured Data
Unstructured data possesses great value, but it also comes at a heavy cost. While it is very costly to maintain data lakes, it is also costly to assemble teams to develop and analyze these huge reserves and extract useful value. Costlier still are the Financial and Reputational implications, if unstructured data is managed badly and is leaked into the wrong hands.
It is therefore important for organizations to develop robust infrastructure security practices alongside using better security tools. Obvious practises like storing unstructured Data in a singular place rather than silos as much as possible, monitoring database activities, and managing a good infrastructure access can go a long way.
For organizations operating in heavily regulated industries like healthcare, finance, insurance et cetera, it is common to have non-standard data in the form of patient reports, hand filled forms, non-standard bank reports etc. Sensitive data discovery, labelling and classification in this case can generally be performed using the following two ways—
1. Using Heuristics
Semistructured data containing explicitly defined data fields, such as name, numbers, IDs or information that adheres to certain patterns for example, license numbers, SSN numbers, email IDs, phone numbers etc. can easily be extracted from forms and documents by the use of predefined regex patterns and/or some smartly defined heuristics.
-
Regular Expressions (Regex) - Regular Expressions are extremely powerful as with a single line of code as they can potentially capture infinitely many occurances of a certain pattern without fault. With effectively including them in the processing pipeline organizations can extract and hide this data from public access. For example, a regex that effectively captures all email addresses looks like this:
^[a-zA-Z0-9_.+-]+@[a-zA-Z0-9-]+\\.[a-zA-Z0-9-.]+$ -
Heuristics for non-standard data fields - A person's name remains sensitive, whether it appears as full name, separate sections for first and last name, inverted name where the last name appears first or just initials contained in the signature. A robust security tool employed to extract and secure this information needs to be able to handle all these cases at once. Well-defined similarity searches like approximate string matching (fuzzy string match) can be used along with other methods to ensure data fields are captured, despite how they are defined in a form or a document.

2. Using AI to capture Implicit Information
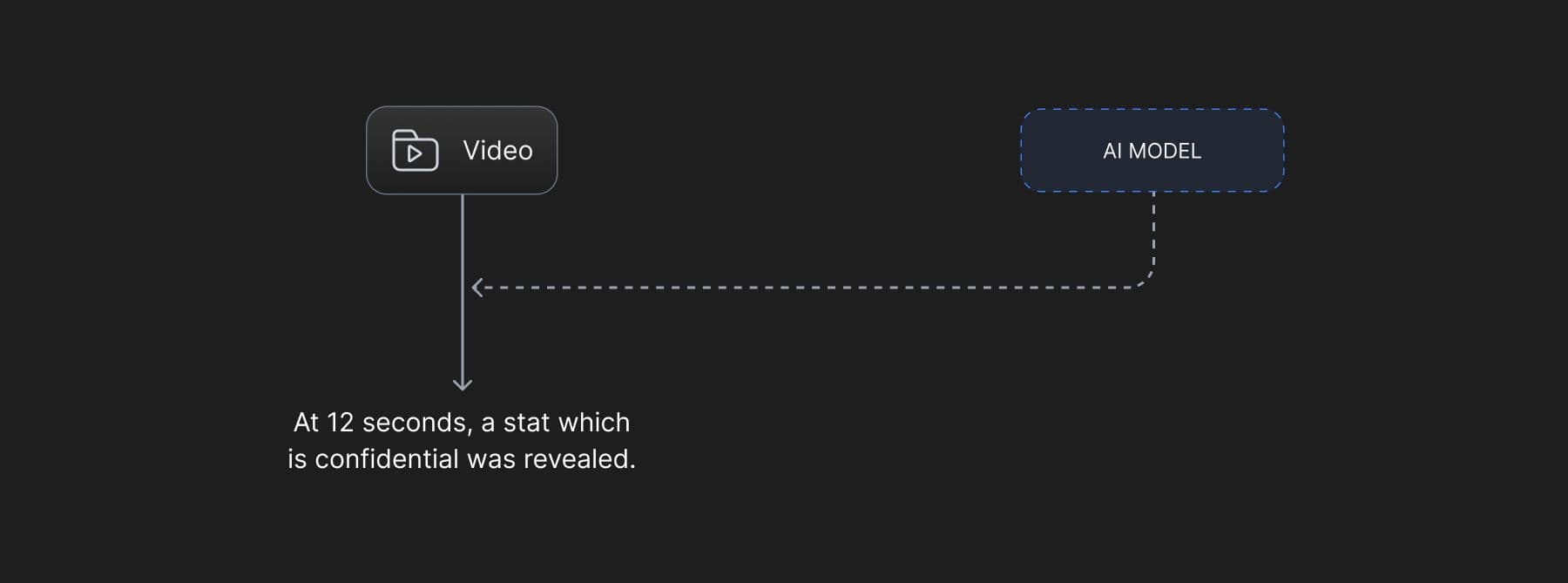
It is common for organizations to have confidential information and by human error display it on a slide to the wrong audience. Any algorithmic tools designed to check any such confidential information should be robust and fault tolerant to all possibilities and require teams to look beyond using just heuristics. Unstructured data like videos, images and slide decks, apart from including names, phone numbers, emails addresses can also implicitly include confidential graphs, comments, or stakeholders. These implicit bits of information cannot easily be identified by heuristics.
Well defined AI, architectures can scan, effectively capture and secure all such information, making it unavailable for a general user without having privileges.
Understanding your Organization’s Data better with Adaptive
Adaptive offers a Database Activity Monitoring Solution, that builds on the existing tools’ capabilities, and introducing novel and extremely powerful features and monitoring techniques. Within its architecture sits the Data Labelling module, responsible for identification of sensitive data for better data security posture management.
Adaptive offers capabilities to identify sensitive information in both Structured Data Databases as well as Unstructured Data Reserves. Once labelled, the organization can use the classification capabilities and define policies for effective monitoring and robust security posture.



Contain the chaos.
 SOC2 Type II
SOC2 Type II